News
New natural language AI model (LUKE) tops SQuAD v1.1 dataset leaderboard
A research team, including researchers from Studio Ousia, released a new natural language processing AI model “LUKE” and it ranked #1 on the SQuAD v1.1 leaderboard, scoring higher then models such as BERT (Developed by Google in 2018), XLNet (Developed by Google in 2019) and SpanBERT (Developed by Facebook in 2019). SQuAD v1.1 is a world renown question answering dataset, consisting of 100,000+ question-answer pairs on 500+ articles based on Wikipedia articles.
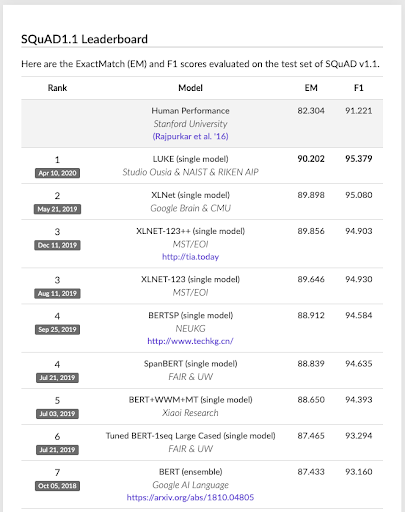
Screenshot of SQuAD v1.1 leaderboard as of April 24, 2020.
https://rajpurkar.github.io/SQuAD-explorer/
Contextualized embeddings is an emerging branch of techniques in used in AI models such as BERT and XLNet to conduct natural language processing tasks. These models are known to have accurate language understanding, but have difficulty in learning real-world knowledge.
LUKE is a new model that consolidates knowledge written in Wikipedia around entities (Wikipedia entries) and thereby has learned various real-world knowledge with high precision. With the model’s detailed knowledge of our world, the model performs well against practical natural language processing problems. Also, LUKE has outperformed advanced models such as BERT and XLNet in ReCoRD, a large-scale reading comprehension dataset which requires common knowledge and commonsense reasoning, and topped the leaderboard.
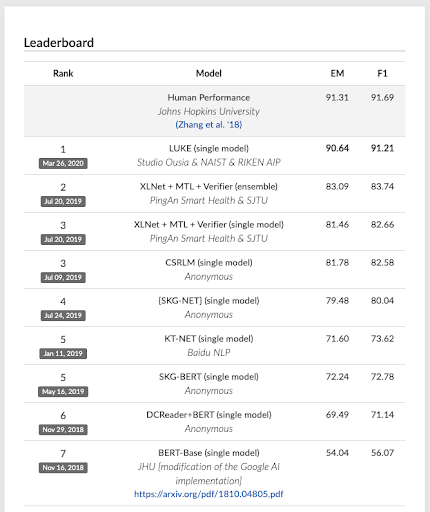
Snapshot of ReCoRD leaderboard of April 24, 2020