News
日本語データで高い性能を獲得した新しい言語モデルLUKE Japaneseを公開
News
2022-11-17
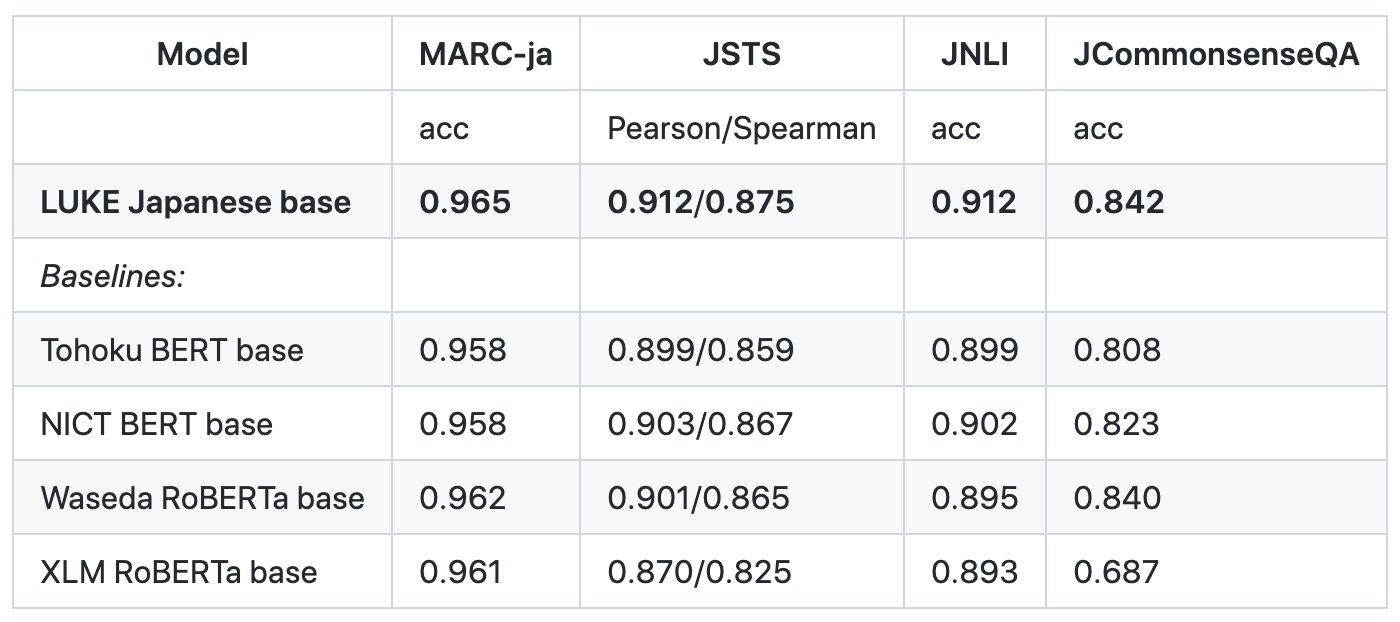
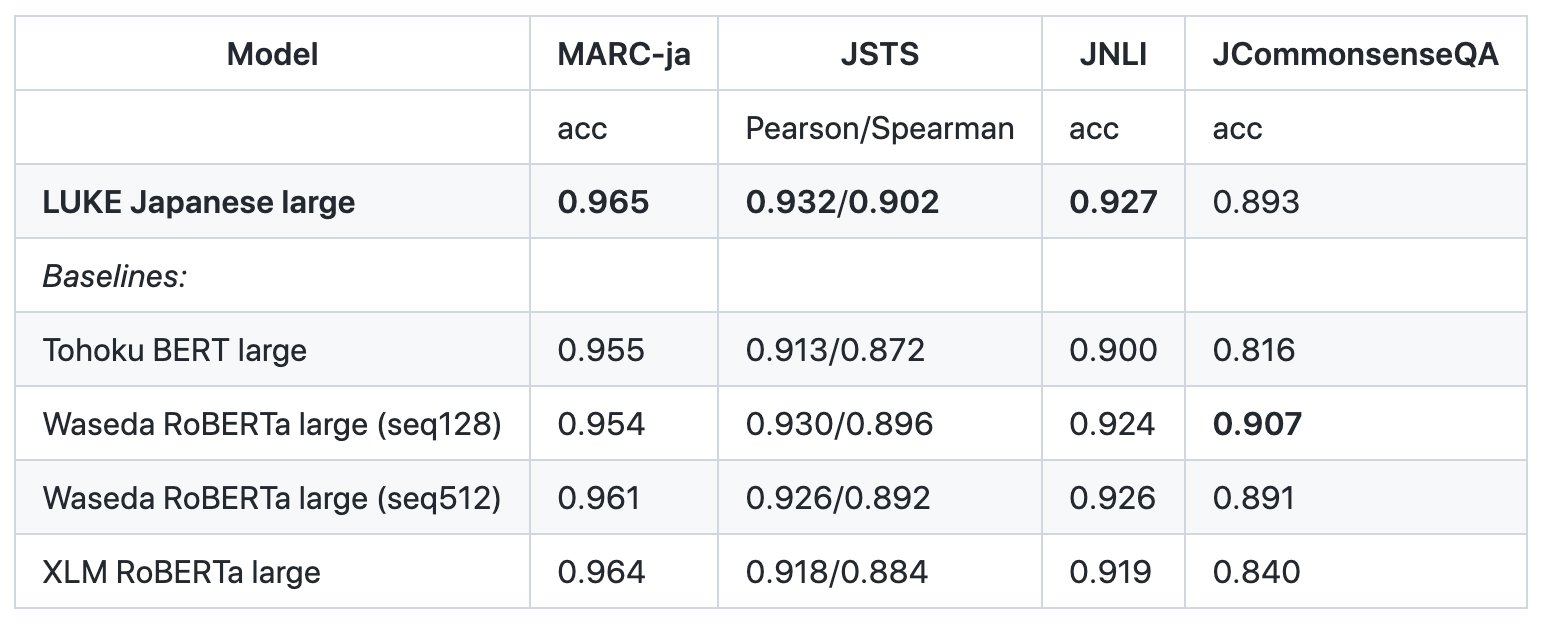
弊社の研究者が中心となって開発した高性能言語モデル「LUKE」の日本語モデルを訓練し、公開いたしました。このモデルは、Yahoo! Japanの開発した日本語自然言語理解のベンチマークであるJGLUEに含まれるデータセットでTohoku BERTやWaseda RoBERTaをはじめとする既存の言語モデルをこえる性能を獲得しています。
日本語LUKE baseモデルの評価結果
日本語LUKE largeモデルの評価結果
また、JGLUEに含まれる一般的な自然言語処理タスクの他にも、LUKEの原著論文で良い性能を獲得した固有表現抽出、関係抽出、エンティティリンキング等においても良い性能が期待できます。
LUKEは、Huggingfaceのクラウド上で公開されており、同社のTransformersライブラリから簡単にご利用いただけます。
LUKEは弊社の研究者が中心となって開発した新しい知識拡張型(knowledge-enhanced)言語モデルです。独自開発の技術(masked entity prediction, entity-aware self-attention mechanism)を活用することで、言語モデルが獲得している知識に加え、Wikipediaなどに蓄積されている世界に関する知識をより詳細に獲得しています。
関連リンク
エンティティを入力として使わない一般的なNLPタスクには、liteモデルを利用してください。
- baseモデル(full):https://huggingface.co/studio-ousia/luke-japanese-base
- baseモデル(lite):https://huggingface.co/studio-ousia/luke-japanese-base-lite
- largeモデル(full):https://huggingface.co/studio-ousia/luke-japanese-large
-
largeモデル(lite):https://huggingface.co/studio-ousia/luke-japanese-large-lite
-
NLPコロキウムでの解説(日本語): https://nlp-colloquium-jp.github.io/schedule/2021-11-17_ikuya-yamada/